
How LiveRamp Rebuilt a Data Pipeline Service to Cut Processing Time by 90%

At LiveRamp, we help customers improve campaign performance through audience onboarding and activation workflows. One way we enable this is through stateless direct delivery. Another is by building stateful audience datasets through what we call onboarding.
Stateful audience building is powered by four stages in the onboarding data pipeline: ingestion, compilation, activation, and delivery. The team I’m with, Dataset Management (DsM), owns compilation – we build and maintain audience datasets, append and remove data, and support compliance requests across petabytes of data.
Beyond the main compilation workflow, DsM also supplies data to other internal teams in the formats they need. One of those services is Import Anonymously Identified Fields (AIF) Preparation, or IAP, which was built for the Activation Backend (ActBe) team to support their Import Potential Reach (IPR) service.
IPR calls IAP to obtain import data and estimate how effectively an import would reach target audiences if activated – before activation actually runs.
.png)
Enhancing Backend Data Pipelines
LiveRamp is dedicated to continuous innovation, and one of the team’s focus areas is enhancing the backend systems.
After evaluating several big-data vendors, we chose SingleStore as our next-generation framework. Teams across LiveRamp began building proofs of concept and migrating Hadoop-based services onto SingleStore. Early results showed strong potential to reduce processing time while lowering compute and storage costs.
DsM started building SingleStore-based services as well, but supporting every customer required a large feature surface on the new stack. To manage that complexity, customer migrations were phased incrementally. As the capabilities a customer depended on became available on SingleStore, we rerouted their traffic onto the new stack.
That approach let us prioritize critical functionality first while keeping the migration invisible from the customer’s point of view. Once the underlying features of DsM stabilized on SingleStore, we started planning for the next-gen IAP to unblock the customers who relied on it.
How the legacy system worked
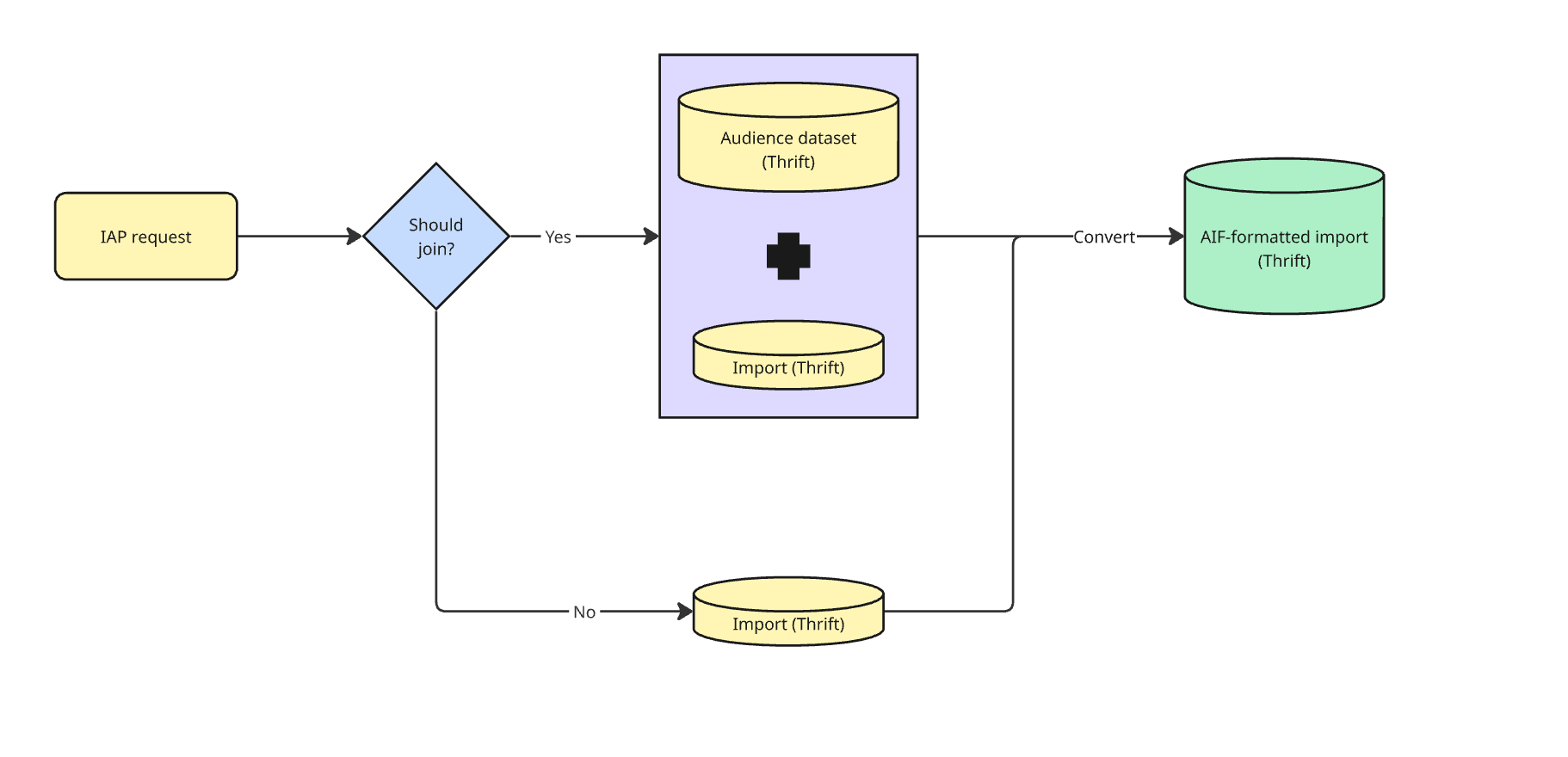
IAP starts when ActBe creates an IAP request. A workflow kicker daemon picks it up and kicks off processing. Each request includes an import ID and several processing settings. Given a valid import ID, IAP loads the import data, determines whether it needs to be joined with the audience dataset, and launches a Hadoop job accordingly.
If no join is required, the workflow is relatively simple: transform the import from one Thrift format (AR) into another (AIF).
If a join is required, the workflow becomes much heavier. IAP reads both the import and the audience dataset, left-joins them to obtain identifier data, and writes sorted AIF Thrift files for downstream systems.
How LiveRamp rebuilt the data pipeline service
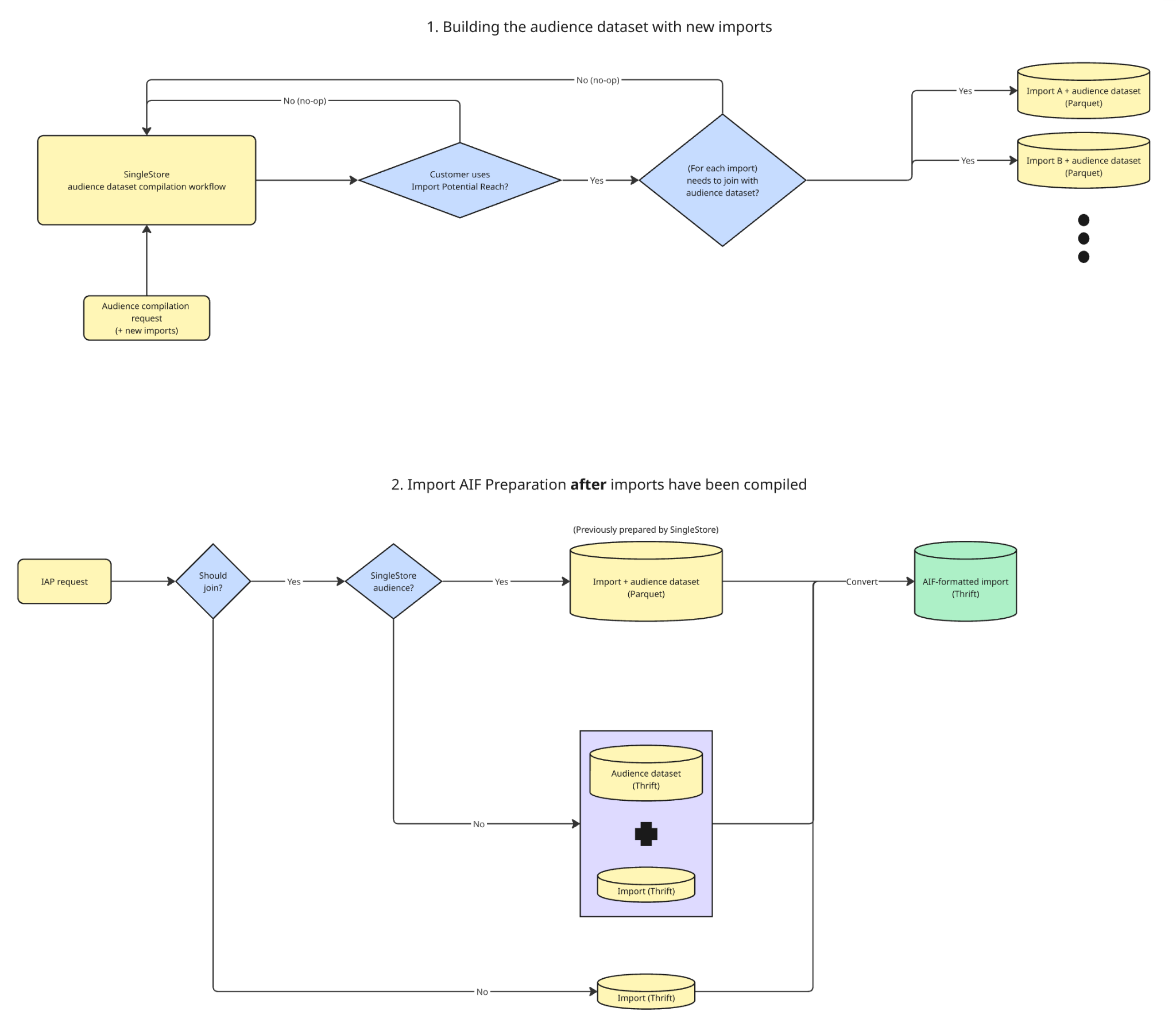
The biggest architectural change in the data pipeline was how the service obtained audience datasets for SingleStore-migrated audiences.
In the legacy workflow, IAP pulled audience datasets directly and performed joins itself inside Hadoop jobs. In the new SingleStore workflow, a SingleStore service supplied audience-joined import data directly to IAP in Parquet format. That means IAP no longer needs to run the expensive join logic itself for migrated audiences – it primarily converts Parquet into AIF Thrift output.
By moving expensive join operations upstream and supplying audience-enriched data directly from SingleStore, the new architecture eliminated a significant amount of distributed processing inside IAP itself. This reduced operational complexity, lowered compute overhead, and dramatically improved turnaround times for migrated audiences.
For customers using Import Potential Reach, those architectural improvements translated directly into faster audience evaluation workflows and quicker paths from import to activation.
Data pipeline performance results
The migration produced significant improvements in both cost and turnaround time.
IAP compute costs dropped about 76% savings on average. Request turnaround time dropped from 8,599 seconds to 777 seconds, a reduction of more than 90%.
The biggest drivers were:
- Simplifying join strategies to reduce processing complexity
- Moving more heavy lifting into the Audience compilation workflow
Beyond the performance improvements, IAP also established a cleaner operational foundation for future SingleStore-native audience services.
Building faster data pipelines for customer outcomes
While IAP was ultimately an infrastructure modernization project, the impact extended far beyond backend systems.
By simplifying joins, reducing processing overhead, and shifting heavy computation earlier in the pipeline, the team significantly improved how quickly customers could evaluate and activate audience data. Faster turnaround times mean customers can move from import to insight more efficiently, while lower infrastructure costs help LiveRamp scale those capabilities more sustainably across growing datasets and workflows.
The migration also laid important groundwork for future SingleStore-native services, helping position LiveRamp to deliver faster, more flexible audience onboarding and activation capabilities over time.
For the engineering team, the project reinforced an important reality of large-scale modernization: meaningful customer impact often comes from improving the systems customers never directly see.
For more technical reviews and implementation guides, check out LiveRamp’s engineering blogs or reach out to ops@liveramp.com.