
Match-Ready Infrastructure: LiveRamp’s Winning Identity API for the FIFA Club World Cup
.jpg)
When DAZN, a global sports streaming and entertainment platform, turned to LiveRamp to power authenticated ad targeting during the 2025 FIFA Club World Cup, we faced one of the largest real-world scaling events in the history of our identity API. Traffic wasn’t just expected to grow – it would come in repeated bursts, timed with the biggest moments of the tournament. Our team knew we'd need to absorb that load without risking the experience of any other customer.
Here’s how we built a game plan for those predictable spikes, why reactive autoscaling couldn’t keep up, and how an event-driven approach kept our platform performing at championship level under 6-7x our normal load.
Key takeaways
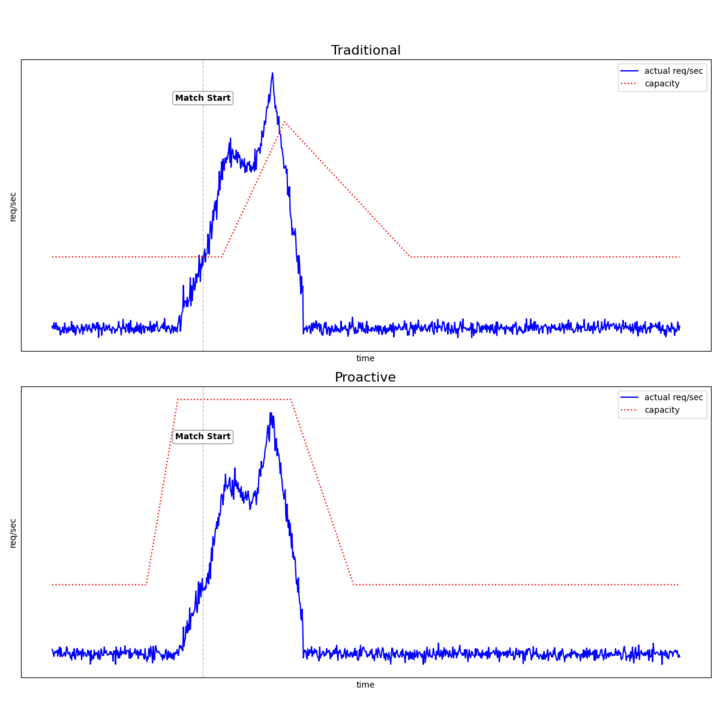
- Predictable, time-bound traffic spikes require proactive—not reactive—scaling. Kubernetes HPA and metric-based autoscaling can’t provision fast enough for event-driven patterns like pre-match authentication surges.
- Scheduled, event-driven scaling eliminated latency and failures. Pre-heating infrastructure via CRON allowed Bigtable, node pools, and pods to be fully ready before traffic arrived.
- Realistic load testing validated capacity under 6–7× normal load. Using Grafana k6, Locust, and a full integration test with DAZN ensured the system could handle 200,000 RPS with zero errors.
- Multi-tenant safeguards protected overall platform stability. Cloud Armor rules served as a kill switch to isolate DAZN traffic if needed, shielding other customers from potential degradation.
- Treat scaling as a capacity-planning problem when patterns are known. By anticipating traffic spikes rather than reacting to them, LiveRamp delivered seamless identity performance during one of its biggest real-world events.
The challenge: Predictable traffic spikes before every kickoff
DAZN’s traffic follows a very specific pattern: Sports fans authenticate via DAZN’s website or app right before a match begins, creating predictable but extreme spikes rather than gradual growth. During the World Cup, authentication requests started 15 minutes before each match, with some users logging in seconds before kickoff.
Our autoscaling relied on the standard Kubernetes Horizontal Pod Autoscaler (HPA), which scales based on CPU utilization. But during high-traffic events, this reactive model wasn’t fast enough. The HPA only adds pods after CPU crosses a threshold, and even then, new pods need time to provision, initialize, and receive traffic. By the time they're ready, existing pods may already be overloaded – causing latency spikes, timeouts, and degraded performance.
Why reactive autoscaling can’t keep up with event-driven traffic
Metrics weren’t our issue – timing was. First, we explored metric-based autoscaling using custom requests per second (RPS) metrics as an alternative to CPU-based scaling. While this approach provided more precise scaling triggers, it couldn’t solve the core issue: reactive scaling happened too late.
DAZN sent authentication API requests as users logged in, with the majority engaging 15 minutes or less before each match. Even with optimized metrics and aggressive scaling parameters, reactive autoscaling couldn't provision and route traffic to new infrastructure fast enough to handle these sharp, predictable spikes.
The solution: Scheduled pre-heating (CRON-based scaling)
We strategically disabled autoscaling for the event and implemented a CRON-based scaler that pre-heated our infrastructure around the FIFA Club World Cup match schedule. This approach allowed us to scale proactively based on known match times rather than reacting to traffic metrics.
Here is a look at our scaling sequence:
- Bigtable instances scaled up first, as they require longer provisioning times
- Kubernetes node pools and pods scaled up 15 minutes before each match
- All infrastructure scaled back down to baseline 15 minutes after match start
This approach gave us several advantages. Our infrastructure was fully scaled before traffic arrived, eliminating the provisioning delays that cause timeouts. We could test and confirm capacity ahead of time instead of relying on tuning guesses. Most importantly, we avoided cascading failures – where overloaded pods trigger scaling actions that come too late to fix the problem.
Load testing and validation
We used Grafana k6 and Locust (our primary tool) to simulate traffic patterns. Through these tests, we confirmed our infrastructure could handle 200,000 RPS – a 6-7x increase over normal traffic and a solid safety margin below the projected peak.
Beyond synthetic load testing, we also coordinated an integration test with DAZN. This test used their actual authentication flow and traffic patterns, giving us confidence that the system would perform under production conditions. The result? Zero errors.
Risk mitigation strategy
Our infrastructure is multi-tenant, so DAZN’s traffic runs alongside traffic from other customers. Even with a solid scaling plan, we needed a backup to protect LiveRamp’s platform if something unexpected happened.
To do that, we added Cloud Armor rules that could identify DAZN traffic using their Origin header and block it if it behaved like a DDoS or pushed the system beyond safe limits. This gave us a kill switch: if DAZN’s load ever threatened overall stability, we could quickly block their requests to keep other customers unaffected. The decision was an important safeguard, prioritizing our commitment to system reliability over a single customer's traffic.
The results
During the tournament, our pre-heating strategy worked exactly as planned – without any errors. The scheduled scaling approach proved reliable, and by treating this as a capacity-planning problem instead of an autoscaling problem, we supported one of the biggest traffic events in our identity API’s history with zero failures and no impact on other customers.
Key lessons for handling extreme traffic events
This experience reinforced several principles for handling extreme traffic events:
- Your scaling strategy should match your traffic patterns. Reactive autoscaling works for gradual growth or unpredictable spikes. For predictable spikes at known times, scheduled pre-heating eliminates the provisioning lag that causes failures.
- Load test with realistic traffic patterns. Synthetic testing validated our capacity, but the integration test with DAZN's actual authentication flow gave us confidence in production.
- Build failsafes for multi-tenant systems. Having a kill switch protected our other customers and gave us options if the traffic exceeded projections.
- Understand your infrastructure provisioning times. Bigtable instances take longer to scale than Kubernetes pods. We sequenced our scaling to account for these differences, ensuring all components were ready before traffic arrived.
The FIFA Club World Cup partnership showed that tackling major scaling events isn’t about chasing traffic – it’s about anticipating the play. By planning proactively instead of relying on reactive systems, we stayed ahead of every spike and delivered a seamless experience for DAZN and all LiveRamp customers, reinforcing the value of partnership and preparation in delivering a dependable identity infrastructure.
Discover how LiveRamp can help you expand your consumer data strategy to reach authenticated audiences at scale, wherever they’re spending time.

.jpg)