
From Hackweek to High-Performance: How Real-Time Caching Cut Costs and Improved Speed
.jpg)
Great engineering solutions often start with a simple question: How can we make this better? That question sparked a Hackweek idea that grew into a production feature with massive impact – one that reimagined how Pylon, our high-throughput RocksDB-backed caching layer, performs at scale.
Why we chose RocksDB:
- RocksDB is an embedded, SSD-optimized key–value store, ideal for large, persistent, local caches with extremely fast reads and writes and no network latency.
- Unlike Redis (RAM-only, networked), RocksDB lets you build a much larger, more cost-efficient cache using disk and memory while still staying fast.
As a rule of thumb, use RocksDB when you need persistent, per-node, write-heavy caching, and Redis when you need shared, distributed, in-memory caching across multiple servers. In our case, we added a RocksDB layer to shard and distribute data across multiple partitions.
Pylon is a critical component of our data ingestion workflow, handling 50 million to 60 million requests per minute. Its performance hinges on cache hit rate. For a long time, the cache was only rebuilt every 15 days, which left us with an 87% hit rate. While that seems high, at our scale it meant 1 million to 5 million requests per minute were missing the cache and triggering expensive calls to our backend graph access service.
This inefficiency meant we were repeatedly making costly identity resolution calls for the same new identifiers before they were added in the next batch cycle. The Hackweek project set out to fix this with a simple idea: What if we could update the cache in real time?
Key Takeaways
- Real-time cache updates replaced slow batch rebuilds, boosting cache hit rates from 87% to over 99% and eliminating millions of redundant backend calls.
- Performance scaled far beyond production needs, achieving up to 900K writes/sec and 2.5M reads/sec without impacting read performance.
- The upgrade delivered major business impact, improving customer speeds, reducing on-call toil, and saving more than $70K per month in infrastructure costs.
Switching to real-time caching: The architectural breakthrough
Beyond reducing backend load, the project was driven by two forces: rapidly growing traffic and our engineering philosophy at LiveRamp. We hold ourselves to extremely high performance standards, and delivering fast, predictable experiences to customers is core to that. To continue meeting—and improving—our SLAs, we needed a smarter, more proactive caching strategy.
Real-time cache updates became the clear solution.
The goal was to let Pylon include new records in the cache the moment they were discovered, instead of waiting for the next rebuild. Achieving this required several architectural changes:
- A new write endpoint: We introduced a new endpoint in Pylon specifically for efficient, real-time put operations. Prior to real-time updates, Pylon supported read-only operations.
- Dataflow for cache misses: We created a series of Dataflow jobs to capture the results of cache misses and immediately write them back to the Pylon cache through the new endpoint.
- Client-side replication: We updated the Pylon client to replicate writes across all replicas within a partition, ensuring durability and high availability.
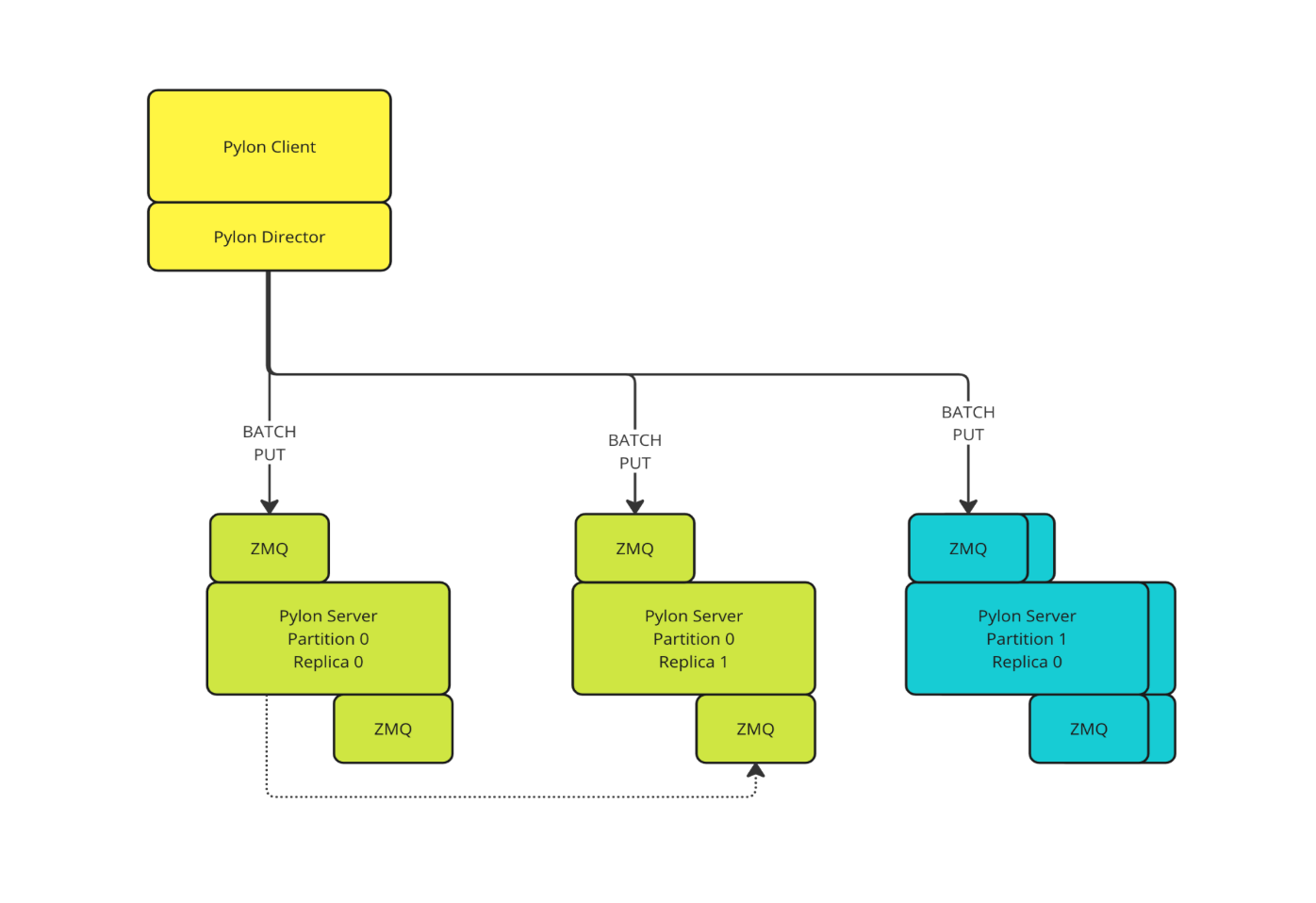
With this mechanism in place, the first time a new identifier is seen, it triggers a single call to our graph access service. That result is then written to the cache immediately, and every subsequent request for the same identifier is served in microseconds from memory.
Performance testing at scale
Before going live, we needed to ensure the new write path could handle production load without degrading read performance. Our system needed to support 17,000 to 83,000 writes per second – the rate of our typical cache misses.
The performance test results exceeded expectations:
- Write-only workload: Peaked at an impressive 900,000 writes per second.
- Read-only workload: Peaked at 2.5 million reads per second.
- Simultaneous read/write: Handled a combined 650,000-700,000 requests per second.
The system delivered write performance approximately eight times greater than our production needs, giving us full confidence in rolling it out.
The impact: Faster performance, higher hit rates, lowered costs
What started as a Hackweek experiment delivered transformative results in production:
- Faster customer experiences: Average turnaround time dropped fivefold, from 20 hours to four.
- Higher performance: Cache hit rate increased from 87% to more than 99%.
- Significant cost savings: Eliminating millions of redundant backend calls saved more than $70,000 per month in infrastructure costs.
- Greater team efficiency: Automation freed the team from about eight on-call days per month, allowing engineers to focus on what they do best: building innovative new features.
This project is a perfect example of our engineering culture in action. What began as a Hackweek idea is now a production feature that improves customer experience, cuts costs, and strengthens the reliability of one of our highest-throughput systems. By investing in smarter caching and real-time data flow, we’ve built a platform that performs better today – and gives us a foundation to innovate even faster tomorrow.


