
The LiveRamp Clean Room and the Need for Speed
.jpg)
The LiveRamp Clean Room is a secure, cloud-agnostic environment that enables data collaboration between brands, agencies, publishers, retail media networks, and platforms. It allows participants to join, analyze, and activate data across partners while supporting strict data governance and usage controls. This capability is powered by a cloud-native data plane architecture that runs entirely within the client’s chosen cloud environment (AWS, Azure, or GCP), supporting data localization and security across multiple zones for high availability.
Apache Spark serves as the underlying processing engine for the clean room, orchestrated by Kubernetes to dynamically scale compute resources based on workload demand. This architecture allows customers to run complex, large-scale analytics across multi-party data sets minimizing data movement outside their own cloud environment.
As clean room workloads continue to grow in size and complexity, the performance of this processing layer becomes critical. Customers depend on the LiveRamp Clean Room to deliver daily insights across terabytes of partner data, often under strict SLAs and cost constraints. Queries frequently involve large joins, heavy aggregations, and scans across columnar data sets. Even small inefficiencies in execution can translate into longer runtimes, higher infrastructure usage, and delayed results. To support these increasing demands while maintaining the same secure and cloud-agnostic architecture, we needed to improve the performance and efficiency of Spark without requiring changes to existing customer workloads.
Key Takeaways
- Clean room performance is critical at scale. As workloads grow to multi-terabyte datasets, even small inefficiencies in Spark execution can impact runtime, cost, and SLA reliability.
- Row-based execution creates bottlenecks for modern analytics. Traditional Spark introduces overhead through JVM processing, memory management, and row-to-column conversions—limiting efficiency for columnar data workloads.
- Columnar, native execution significantly improves performance. By leveraging DataFusion Comet with Apache Arrow, LiveRamp enables faster scans, joins, and aggregations while reducing memory usage and serialization overhead.
- Performance gains come without code changes. Comet acts as a drop-in Spark accelerator, allowing existing PySpark and Scala workloads to run unchanged while benefiting from native execution improvements.
- Faster queries translate directly to business impact. Improved performance reduces infrastructure costs, accelerates insights, and enables more scalable, reliable data collaboration in the LiveRamp Clean Room.
Why we needed to accelerate Spark in the clean room
Several factors drove the need to improve Spark execution performance across our production clean room environments.
Scale challenge: Processing terabytes of cross-media data from multiple partners – including publishers, DSPs, and retail media networks – in a unified view requires significant computational power. Clean room queries often operate on multi-terabyte data sets spread across many partitions and storage systems.
Speed requirements: Customers rely on clean rooms for daily reporting, measurement, and attribution workflows. Insights must be delivered quickly and predictably, but traditional Spark execution, while reliable, cannot always meet the aggressive runtime targets required for production workloads.
Cost efficiency: Clean room workloads run continuously across hundreds of environments. Even modest performance improvements can reduce total cluster runtime, lowering infrastructure costs while allowing more workloads to run on the same hardware.
Data complexity: Clean room queries commonly include:
- Multi-party joins across disparate data sets
- Complex de-duplication logic for accurate reach measurement
- Heavy aggregations for attribution and performance analysis
- Large-scale scans of Parquet and other columnar formats
These patterns are particularly sensitive to memory usage, shuffle performance, and central processing unit (CPU) efficiency.
Resource optimization: Improving CPU utilization and memory efficiency allows us to support more customers on the same infrastructure while maintaining predictable performance for business-critical analytics.
To address these challenges, LiveRamp introduced DataFusion Comet as a native execution accelerator for Spark. By enabling columnar, native execution without requiring application changes, we were able to improve performance while preserving the reliability and compatibility of our existing clean room platform.
Apache Spark performance challenges
Modern Apache Spark is a highly flexible distributed engine capable of processing terabytes of data through structured query language (SQL) or its DataFrame application programming interface (API). Its maturity, extensive connectivity, numerous integrations, and robust design make it one of the most versatile distributed engines available – handling everything from distributed machine learning and graph processing to SQL workloads in data warehouses and lakehouses.
However, this versatility comes at a cost. Due to its resilient distributed data set legacy, Spark primarily uses row-oriented data representation in memory. Despite improvements from Project Tungsten's code generation and vectorized readers, operators still incur significant overhead from Java object creation, garbage collection, and row-to-column conversions.
These costs become especially visible in analytical workloads that dominate clean room processing, including large Parquet scans, wide joins, and memory-intensive aggregations. In these scenarios, Spark can spend significant time managing objects and memory rather than performing actual computation, leading to slower queries and inefficient CPU utilization compared to engines designed for columnar execution.
Entering the columnar era
Row-oriented execution works well for certain types of data, particularly unstructured or semi-structured formats such as text, CSV, or XML. However, modern data platforms, including clean rooms, are built around columnar storage formats such as Apache Parquet, Apache ORC, and table frameworks like Delta Lake, Iceberg, and Hudi.
In these environments, row-based execution introduces unnecessary overhead. Data stored in columnar form must often be converted into rows before operators can process it, and then converted back into columns for output. Even with efficient implementations, these conversions add CPU cost and increase memory pressure.
Clean room workloads are especially sensitive to this overhead because they frequently scan large columnar data sets, perform wide joins, and aggregate across many columns. A more efficient approach is to keep data in columnar format throughout execution and operate directly on contiguous memory buffers.
This shift toward columnar processing motivated us to explore native execution engines that could integrate with Spark, while avoiding the overhead of row-based execution.
The solution: Native columnar execution with Comet
To improve performance without changing the programming model used by our customers, we looked for a way to keep Spark’s optimizer and APIs while replacing the row-oriented execution layer with a native, columnar engine.
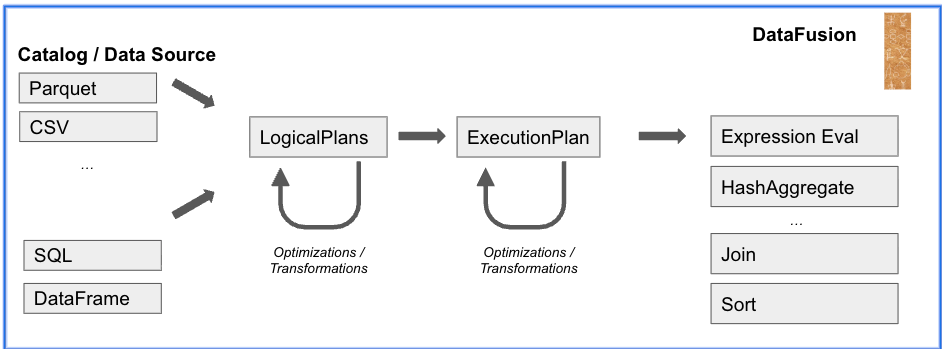
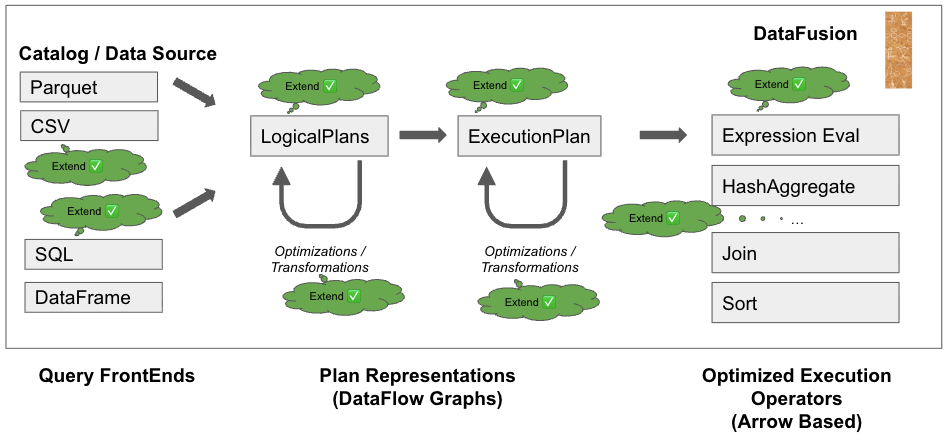
DataFusion Comet provides exactly this capability. Comet is a Spark accelerator built on top of the Apache DataFusion query engine, which is written in Rust and uses Apache Arrow as its in-memory format. This allows execution to occur in native code using columnar data structures, avoiding Java Virtual Machine (JVM) overhead while maintaining compatibility with existing Spark applications.
With Comet, Spark’s Catalyst optimizer still produces the execution plan, but supported operators are executed by the native backend. Unsupported operators automatically fall back to the standard Spark engine, to help maintain correctness and reliability.
This approach allows users to continue using the same PySpark and Scala APIs while benefiting from:
- Single instruction, multiple data (SIMD)-optimized columnar execution
- Reduced serialization overhead
- More efficient memory usage
- Faster scans and joins on columnar data
Most importantly, these improvements require no changes to existing customer workloads.
Key features
- Plan conversion: Converts Spark's physical execution plan to a native backend plan.
- Fallback processing: Leverages the existing Spark JVM engine to check if an operator is supported by the native library. Comet extension automatically detects unsupported features and falls back to the Spark engine.
- Memory management: Uses Spark’s memory manager while executing operators in native code.
- Columnar shuffle: Uses Arrow-based shuffle for more efficient data exchange.
- Shim layer: Supports multiple versions of Spark for seamless integration.
How does Comet work?
Comet is a native Spark query execution plugin that integrates with Spark's plugin framework and extensions API. The driver-based plugin updates Spark configuration with additional executor memory settings. Physical plan optimization rules (CometScanRule and CometExecRule) to determine which operations can be accelerated through native execution.
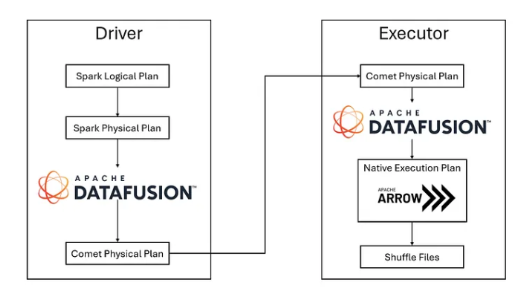
Comet works through org.apache.spark.api.plugin.SparkPlugin:
class CometPlugin extends SparkPlugin with Logging {
override def driverPlugin(): DriverPlugin = new CometDriverPlugin
override def executorPlugin(): ExecutorPlugin = null
}
This design allows Comet to accelerate queries transparently while preserving the behavior of existing applications.
Apache Spark vs. Apache Spark with Comet
Below is a side-by-side comparison of the traditional Apache Spark and Apache Spark with Comet architectures, how they perform, and our benchmark results.
Apache Spark (Traditional) Architecture
Apache Spark with Comet Architecture
Performance comparison
Performance benchmark results
We tested Comet against production clean room workloads across measurement, attribution, and data quality pipelines. Here’s what we found:
Benchmark overview
We tested Comet across production clean room queries spanning various industries and use cases:
- Measurement solutions: Multi-party matched impressions and reach analysis
- Attribution queries: Cross-platform attribution with large-scale joins
- Data quality checks: Retail media network data validation and conversion analysis
- Mixed workloads: Combination of extract transform load and analytical queries
Our production testing revealed significant performance improvements across diverse workload patterns.
These improvements reduced cluster runtime, improved SLA consistency, and lowered total infrastructure usage across clean room environments.
Next steps: Rolling out Comet
We deployed Comet in production through a carefully structured approach, outlined below.
spark.comet.enabled = true
spark.comet.exec.enabled = true
spark.comet.expression.allowIncompatible = false
spark.comet.exec.shuffle.enabled = true
spark.comet.exec.shuffle.mode = auto
spark.comet.scan.enabled = false
spark.shuffle.manager = org.apache.spark.sql.comet.execution.shuffle.CometShuffleManager
These are the deployment phases our team followed:
- Centralized control: Established Comet configurations at the organization level for streamlined management
- Pilot program: Enabled Comet for a select group of clean room queries across multiple environments, testing both SQL and compute workloads while monitoring performance metrics
- Validation: Verified that query results were consistent between standard Spark and Comet-accelerated execution
- Safety net: Maintained the ability to quickly disable Comet organization-wide if issues emerged
We also introduced new instance types to support higher executor memory demands. The new configured off-heap memory allocation became spark.memory.offHeap.size (50g)
Partition tuning strategy
Comet's columnar processing model requires careful consideration of partition sizing to avoid internal buffer limitations. The partition sizing must ensure individual vectors fit comfortably within internal limits, regardless of total available memory. More memory doesn't always mean better safety – proper partition sizing does.
spark.sql.shuffle.partitions = Between 600 to 10000 based on workload complexity
The memory paradox
Comet can spill to disk, but unlike standard Spark, it processes data in large columnar batches instead of row by row, which introduces a unique set of memory management challenges. In a traditional row-based Spark execution model, data is processed incrementally, allowing Spark to spill conservatively when memory pressure is detected and handle large partitions by gradually writing intermediate results to disk.
Comet’s columnar execution model behaves differently. Because it operates on entire vector batches in memory, individual vectors must fit within internal buffer limits (typically around 2 GB for contiguous allocations). As a result, even when sufficient total memory appears to be available, Comet may not trigger a spill soon enough, leading to failures when a single vector exceeds the allowable size.
Shuffle volume
Comet shuffle can show occasional instability under heavy workloads, especially when large shuffle volumes and memory pressure prevent sufficient disk spilling. In these cases, executor failures may occur, requiring a fallback to Spark’s native shuffle to enable reliable job completion.
spark.comet.exec.shuffle.enabled = false
spark.shuffle.manager = org.apache.spark.shuffle.sort.SortShuffleManager
Performance impact and results
Adopting Comet significantly improved both performance and efficiency across LiveRamp Clean Room workloads without requiring any changes to existing Spark applications. By moving from JVM-managed memory to Arrow-based off-heap memory, we reduced garbage collection overhead, lowered heap pressure, and minimized unnecessary spill operations. Comet’s native Rust execution engine, combined with SIMD-optimized columnar processing, delivers better CPU utilization, improved cache locality, and reduced serialization overhead compared to standard Spark execution.
These technical improvements translated directly into measurable business impact. Because Comet operates as a drop-in accelerator for Spark, our existing PySpark and Scala workloads run unchanged, allowing us to roll out performance gains safely across production environments. Automatic fallback to the standard Spark engine supported reliability while enabling us to take advantage of native execution wherever possible. Faster query runtimes reduced cluster runtime across hundreds of clean room environments, lowering infrastructure costs and improving overall resource utilization.
Performance improvements for real customer impact
Now customers get insights faster and large multi-party workloads process more efficiently. LiveRamp is able to support more clean rooms on the same infrastructure while maintaining the performance and reliability required for business-critical analytics. The result is quicker insights, more efficient collaboration, and faster, data-driven decisions made with confidence.
For more technical reviews and implementation guides, check out LiveRamp’s engineering blogs or reach out to ops@liveramp.com.
Frequently asked questions
When should you consider optimizing Apache Spark performance?
Organizations should prioritize Spark optimization when running large-scale analytical workloads—such as multi-terabyte joins, attribution modeling, or cross-partner data processing—where runtime, cost, and SLA consistency become critical.
What types of workloads benefit most from columnar execution?
Columnar execution is especially beneficial for analytical workloads like large scans, wide joins, aggregations, and reporting queries that operate on structured, columnar data formats such as Parquet.
Does improving Spark performance reduce infrastructure costs?
Yes. Faster query execution reduces total cluster runtime and resource usage, which can lower compute costs and allow more workloads to run on the same infrastructure.
What are common bottlenecks in distributed data processing systems?
Typical bottlenecks include inefficient memory usage, data serialization overhead, shuffle performance, and excessive CPU time spent on data format conversions rather than computation.
How do organizations balance performance improvements with system reliability?
Many teams adopt incremental rollout strategies, such as pilot programs and fallback mechanisms, to validate performance gains while ensuring production workloads remain stable.
Why is performance especially important in data collaboration environments?
In multi-party data environments like clean rooms, performance impacts not only individual queries but also shared workflows, partner SLAs, and the ability to deliver timely, actionable insights.