
What is big data engineering?
Big data engineering is the process of optimizing information by enabling businesses to acquire, clean, identify, store, and effectively use that data to achieve desired outcomes. Data is only useful if it is organized and analyzed into logical groupings. Big data engineering can be highly beneficial for businesses to help them improve their efficiency, scalability, and, therefore, profitability.
What is big data?
Big data refers to massive sets of structured and unstructured complex information, too large to manage with traditional software, based on volume, velocity, variety, veracity and value.
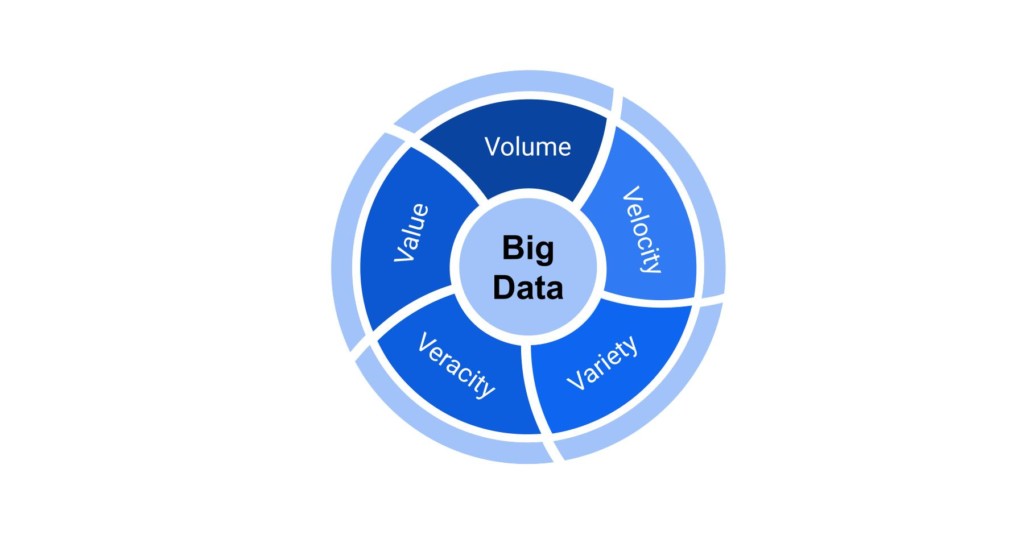
- Volume: In the normal course of business, companies easily have terabytes of data (trillions of bytes) and some petabytes (millions of gigabytes)
- Velocity: The rate data is received from various sources
- Variety: Various data types usually unstructured
- Veracity: Trustworthiness via accuracy, quality, and consistency
- Value: Usefulness via the insights it provides
The Bureau of Labor Statistics (BLS) defines big data as “a collection of large datasets that cannot be analyzed with normal statistical methods. The datasets are so big, they are measured in exabytes—one quintillion (1 followed by 18 zeros) bytes. […] The data do not have to be just numbers; they can be videos, pictures, maps, words and phrases, and so on.”

What is a big data engineer?
A big data engineer is a technically trained engineer, data scientist, statistician, or analyst who manages, interprets, and gains actionable insights from large data sets. Managing data includes, but is not limited to, extracting, maintaining, analyzing, testing, and evaluating information that meets companies’ needs. Big data engineers are critical to companies globally, and are only getting more in demand each year.
Big data engineer vs. data scientist
Big data engineers focus on building and maintaining systems and processes that collect as well as extract data. Data scientists focus on analyzing clean data in order to glean meaningful insights via predictive modeling.
Data engineering personas
For those who are interested in becoming a big data engineer, these are characteristics that describe a typical big data engineer’s persona:
- Enjoys problem-solving
- Possesses a passion for computer science
- Learns about databases and data integration
- Organizes and cleans chaotic information into accurate, actionable data
If these characteristics match your interests, a career as a big data engineer will prove to be very rewarding.
Big data engineer job description
LiveRamp engineering example job description: Senior Software Engineer, Big Data
About you:
- 4+ years of experience writing and deploying production code, with at least 2+ years experience working on a big data platform
- Experience with data processing platforms such as Hadoop, Spark, Hive, Pig
- Understanding of large-scale data processing systems and distributed databases
- Solid programming skills in Java/Scala, C++ or Python
- Understanding of automated QA needs related to big data
- Experience with cloud providers like AWS, Azure, GCP
- Bachelors or masters degree in computer science, information technology, engineering, a related field, or commensurate work experience
Bonus points:
- GCP
- Kubernetes
- Spring boot
- Stream processing – Spark streaming, Apache Kafka, Apache Storm, Flink
- Search indexing such as Lucene, Solr, Elasticsearch
- Modern datastores such as MongoDB, Cassandra, SingleStore, Snowflake, Aerospike
- Experience as a formal tech lead
- Designing and implementing interfaces and infrastructure for large-volume services and RESTful APIs
Big data engineer job responsibilities
Big data engineers are responsible for creating massive big data reservoirs and distributed systems that are fault-tolerant and extremely scalable. These systems store and process huge, rapidly changing data streams.
Example responsibilities:
The LiveRamp data lake team provides cutting-edge data access capabilities to our customers at petabyte scale. We are now evolving our system into a modern, cloud-agnostic, SQL-based data warehouse. You will immediately have an impact in solving our most challenging problems.
You will:
- Work on a massively scalable data management system that performs operations on petabytes of data with real-time segmentation. If you enjoy advanced distributed databases and indexing strategies, this could be a good fit.
- Tackle challenging problems such as implementing SOA and Kubernetes at scale and overhauling our data tier on GCP and beyond.
- Own product features from the development phase through to production deployment.
- Evaluate big data technologies and prototype solutions to improve our data processing architecture.
Your team will:
- Provide advanced data lake and segmentation capabilities to our internal and external customers.
- Iterate on our next-gen architecture as we aim to support streaming and real-time use cases.
- Discover and deliver innovative solutions to our customers’ most difficult challenges at mind-boggling scale.
Skills required for big data engineering:
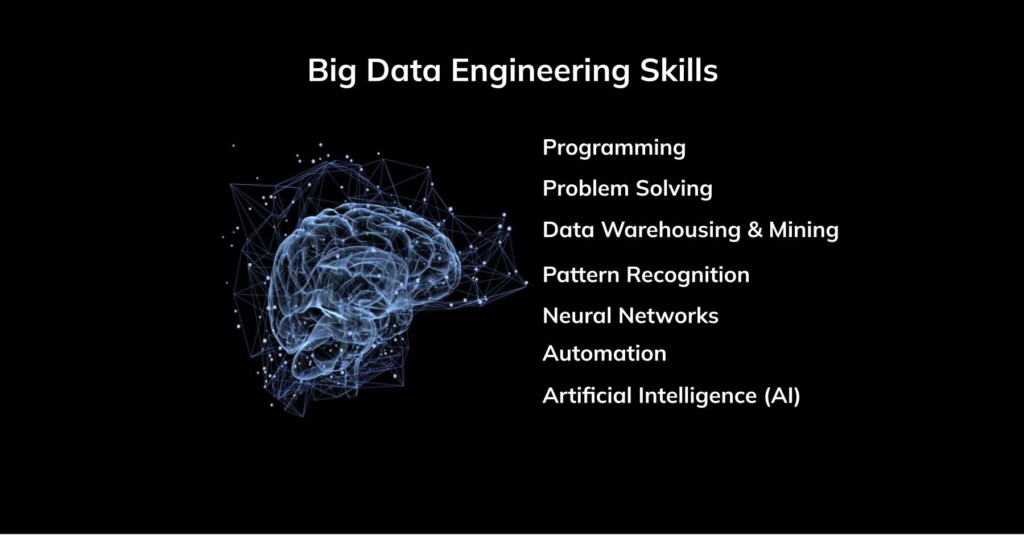
Here are some specific technical areas in which big data engineer professionals need to be proficient for this career:
- Computer programming (e.g. C++, Java/Scala, and Python)
- Operating system knowledge for Linux, BSD/Unix or Windows
- Data mining, modeling, visualization, and warehousing
- Streaming, Apache Spark and Hadoop
- Database architectures
- Cloud computing
- Data modeling
Important capabilities of big data engineering
- Technical degree in computer science, statistics, data analytics, or related fields
- Experience (freelancing, interning, etc.)
- Certifications such as:
Big data engineers are generally masters of coding, statistics, and data. Most companies require a bachelor’s degree for big data engineer positions.
How big data evolved into data engineering
Analyzing large amounts of data is key to data management and using data effectively. Traditional technologies such as Yarn, MapReduce, Hadoop, and others are not as scalable as cloud computing tech that has risen to foster a data engineering culture. Companies have realized that cloud computing has enabled scalability with tools such as Kafka and Spark. As a large-scale data streaming platform, Kafka is widely used by companies globally. Similarly, Spark’s ability to provide 100 times more data processing speed than Hadoop sets it apart, enabling the use of data analytics as well as machine learning. These technologies have fostered a move from big data (as a standalone reference) to the craft of data engineering, which helps organizations accurately predict behavior and trends.
Data engineering: essential successful use of artificial intelligence (AI) and analytics
For some time, enterprise companies have struggled with using AI due to a lack of data and an inability to bring data and analytics into production (source Databricks).
Steve Lohr of The New York Times said: “Data scientists, according to interviews and expert estimates, spend 50 percent to 80 percent of their time mired in the mundane labor of collecting and preparing unruly digital data, before it can be explored for useful nuggets.”
Data engineering provides accurate, clean data that is trustworthy for AI and analytics projects.
Big data engineer salary
According to PR News Wire, “Dice’s 2022 Tech Salary Report shows that average tech salaries are at an all-time high, and up more than 7% year over year versus the national average of 4% (SHRM).”
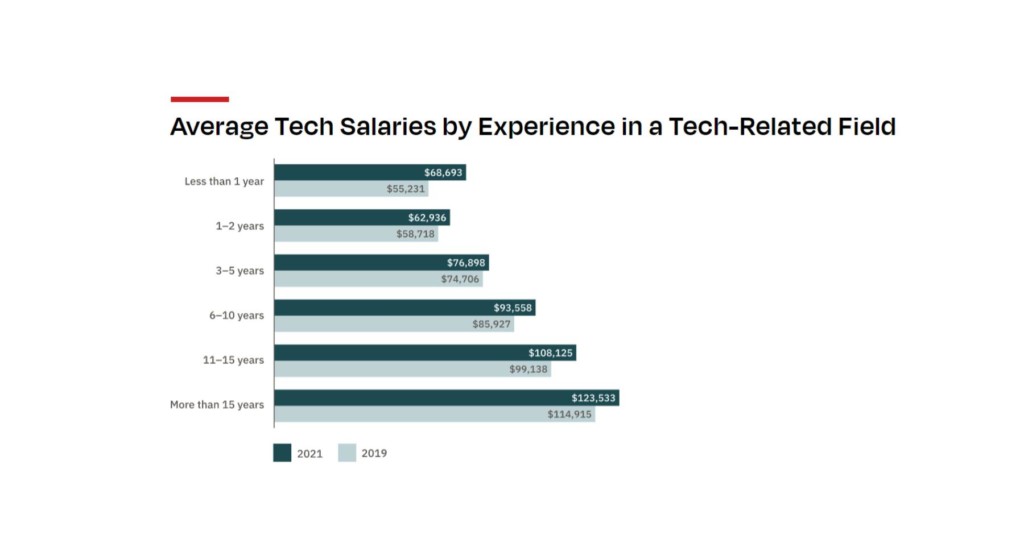
Image source Dice

Image source PR Newswire
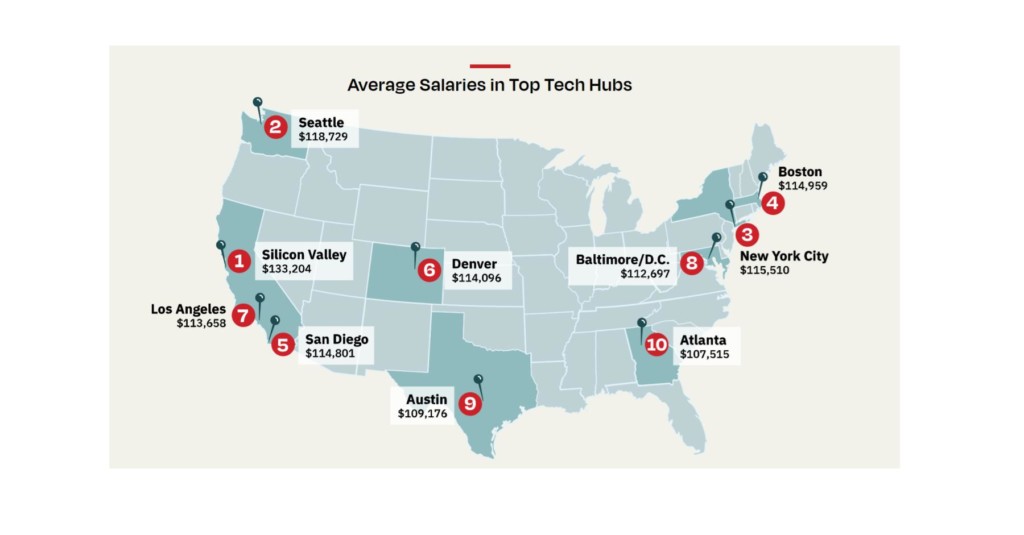
Image source: Dice*
*Dice also provided the following caveat: Early-career big data engineers with little experience can expect to make less, while highly experienced big data engineers can make more.
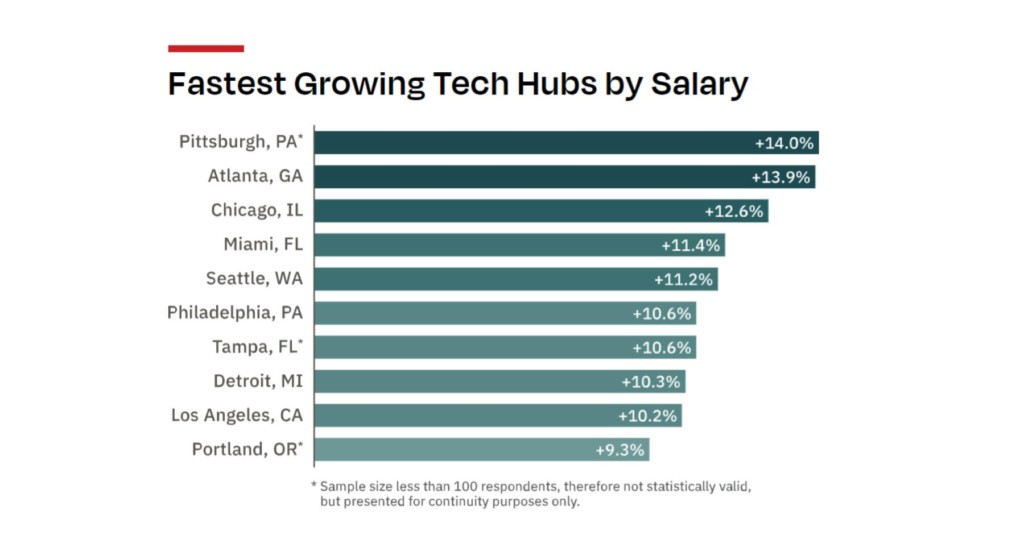
Dice also evaluated Tech Hubs by typical salaries:
Big data engineering job outlook
“Employment of computer and information research scientists is projected to grow 22 percent from 2020 to 2030, much faster than the average for all occupations,” according to BLS. ZipRecruiter reports that there are currently 1,174,646+ data engineer jobs available as of August 16, 2022, in the U.S.

Image source: Executive Levels
The industry projects a huge rise in demand for big data engineers. According to BLS, big data engineering jobs (categorized as mathematicians and statisticians and computer and information research scientists) are on a growth path to achieve between 22-33% by 2030.
Dice reported in 2020 that the global demand for big data engineers increased by 50% in one year, implying a shortage of skilled labor.
Organizations globally have a critical and growing need for big data engineers to help them to analyze, organize, and extract insights from many sources. Big data engineering is the future, and a great opportunity for a rewarding career.
According to PR News Wire:
- More than one million tech roles remain unfilled across the U.S. economy
- There are fewer than 85,000 new computer science graduates entering the workforce each year
- The largest growth by job classification across all industries is for software engineers, with postings up 162% since May 2021
According to the World Economic Forum, by 2025, 97 million jobs will emerge in the following growth areas:
- Data analysts and science
- AI and machine learning
- Big data
- Digital marketing and strategy
- Process automation
- Business development
- Digital transformation
- Information security
- Software and applications development
- Internet of Things (IoT)
How to become a big data engineer?
Refer to the skills summary above and consider an advanced degree in data visualization, analytics, data mining, and predictive modeling. In addition to these technical skills, also build your interpersonal and business skills to hone your collaboration prowess, as solving big data problems also requires teamwork and creativity.
Your future is bright as a big data engineer with challenging work, competitive compensation, and great company with the world’s top problem-solvers.
As a market-leading big data company, LiveRamp has a world-class engineering organization that is made up of top talent engineers who have created the largest identity graph in the world. That is big data at its best. To effectively handle this much data, we have some of the best engineers in the world as teammates.
LiveRamp is a data enablement platform designed by engineers, powered by big data, centered on privacy innovation, and integrated everywhere.
Enabling an open web for everyone.
LiveRamp is hiring! Subscribe to our blog to get the latest LiveRamp Engineering news!