
Embedded Identity Solutions: How LiveRamp is Transforming Data Collaboration in the Cloud

Varun Nair, Ashitosh Dhapate, and Sean Kimball contributed to this blog.Privacy, security, and simplicity are cornerstones of LiveRamp products. To accommodate all customers’ data needs, LiveRamp’s identity solutions are available in the cloud of your choice in any geographic region. With partners like Snowflake, it also means your data never leaves your account, and you can manage how much data to compute in the identity resolution or translation process.As the data collaboration platform of choice for the world’s most innovative companies, LiveRamp offers cloud embedded solutions across various platforms so customers can resolve data in your own environment. Currently we have embedded solutions across Snowflake, AWS, and GCP. We are actively working on enabling these solutions across other cloud platforms like Azure, Databricks etc. In this blog, we will touch on three cloud solutions you can use to resolve customer data: the LiveRamp Snowflake Native App, the Amazon Data Exchange offering, and the Embedded GCP application.
Snowflake
Starting with Snowflake, Snowflake Native Apps provide an interface for data providers to share data and related functions or procedures with data consumers while hiding away implementation details for the procedures and functions and the underlying data being shared if needed. The privacy controls around data sharing and easy use make it an ideal mode to deliver LiveRamp’s Identity solutions to clients on Snowflake. Below is a diagram showing the same.
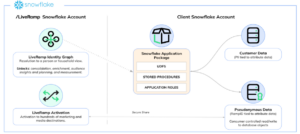
Identity resolution relies on a third-party reference graph. This data, along with functions and procedures, is shared by LiveRamp’s Snowflake account in a particular region with customers in that specific region. The data shared by LiveRamp is hidden from the customers and is only accessible through interface procedures. This essentially replicates some of the functionality of LiveRamp's other systems, which are available through UIs/APIs. Customers can use this data in your accounts to resolve the issue.During this process, the data doesn’t move out of your account, and you maintain full control over customer data as well as the data generated by LiveRamp’s solution. This process provides robust privacy and security.Some of the challenges we faced while implementing this were:
- When we started implementing, the only two languages supported for functions and stored procedures were Javascript and SQL (today, Snowflake supports other languages, including rich library support for Java, Python, and Scala).
- The Javascript library support was(is) limited within Snowflake, and there are size limits to functions/procedures in Javascript. So, we had to add inline minified JS libraries in certain cases, and in others, we had to convert large portions of JS code to SQL. Eventually, with Java support in native apps, we were able to port existing libraries into the app.
- We did not want our authentication system to be fragmented, so we authenticated users using Snowflake’s external function features.
- We also needed to extract metrics for each job run for billing purposes. Snowflake shares helped in this such that the app writes out its metrics to a table on the customer end. Then each customer sends us back a share of these metrics and we validate them for each job. This helps us in enforcing that we capture the metrics before releasing the output, a feature that Snowflake has made great strides in supporting since our initial launch.
- We also developed a homegrown testing and deployment framework for our code using Pytest and Jinja. At the time, there was no standard way in which code written in the editor spanning multiple procedures, tables, and functions could be easily pushed to Snowflake. So, as multiple developers were working on the project, it was an immense productivity boost to do it in a standard way. This has also been incredibly helpful in ensuring quality as we have added more features over the last couple of years. CI/CD is at the heart of our development process for LiveRamp’s Snowflake Native App.
- Snowflake has since then released templates on how to run/deploy projects. The snowcli tool with support for native app standardizes setups(project folder structure) and makes it easier to do deployments. They also have UI tools to help with this.
- Performance tuning has been a major undertaking for us, especially in our PII workloads. We need to optimize the time taken to join incoming customer data(sometimes hundreds of millions of rows) against our reference dataset(billions of rows) so as to minimize computation and, hence, cost for our end user. This has been an iterative process in which we made 200x improvements from where we started over the course of multiple iterations in a year.
The Native Application Framework ensures you can maintain control over your data. Over the past few years, we've been able to dramatically advance and optimize throughput, ensuring we deliver an accelerated time to value for client workflows. We continue to work on new innovations and features to better serve customers in Snowflake.
Amazon Data Exchange
Next, our identity integration in Amazon Data Exchange (ADX) is another example of embedded identity that has provided value to our customers. ADX is a service provided by Amazon Web Services (AWS) that allows data providers to publish their data products and data subscribers to find, subscribe to, and use these data products in their own AWS environment. ADX ensures secure data sharing, data licensing and billing, compliance, and governance of the data, which makes it a robust and trustful service and ideal for LiveRamp to deliver its solutions.This offering enables clients to perform identity resolution and translation right from their AWS environment. As discussed above, identity translation is an algorithmic process, while identity resolution works on the reference data. LiveRamp’s internal system in AWS performs these computations and processes.
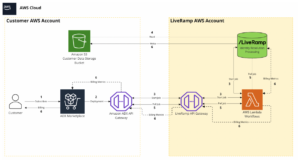
The above diagram shows a high-level architecture of LiveRamp’s ADX offering. Here is how it works:
- Customers subscribe to this product through the ADX marketplace.
- Provide access to LiveRamp for a desired S3 location in their account, which will be used to provide input data to LiveRamp.
- Use AWS data exchange curl request to invoke the start_job lambda function which will validate the input and kick off processing in LiveRamp’s system and return a job_id to the customer.
- Customers can track the job status by invoking the poll_job lambda function. They will provide the job_id and desired S3 bucket to receive the output.
- LiveRamp will process that data through an internal system and deliver the output in the client's preferred s3 location.
One of the challenges we faced in designing this product was keeping computations and processing optimized. The AWS gateway's default timeout is 29 seconds (it was increased to a maximum of 90 seconds in the last few months), and this can not be changed. Customers usually resolve millions of rows through ADX, so we had to design some functionalities to run asynchronously and return the initial response within the timeout period.This offering also powers the AWS entity resolution service. AWS Entity Resolution is a managed service that uses rule-based matching and machine learning to match accurately and link related records across multiple data sources, helping organizations create a unified view of their data and improve data quality. Customers can also use AWS entity resolution service by selecting LiveRamp as a partner for identity resolution and translation.
GCP BigQuery
Finally, we offer embedded identity in GCP through a set of sharable stored procedures in BigQuery. BigQuery is a hosted SQL solution that scales well to the larger datasets our customers can provide. Through role-based access controls, BigQuery allows LiveRamp to securely share identity translation and resolution with customers and offers them a way to execute LiveRamp’s identity functions from their own GCP environment.
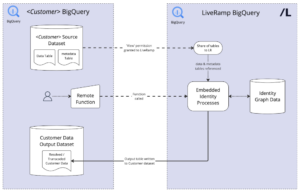
As shown in the diagram, customers can perform translation and resolution after a few steps:
- Customers provide read access for their data to LiveRamp by granting a LiveRamp service account the data.viewer role. They also grant LiveRamp access to write the output tables to a dataset by granting the service account to the data.editor.
- LiveRamp will share access to a stored procedure for the customer to call in order to start identity translation or resolution jobs.
- Customers will provide the required tables for the stored procedure and start jobs as needed.
- They can track jobs via the job_id returned by the stored procedure and querying the job table that LiveRamp creates in the dataset LiveRamp has been granted edit access to.
- Once the job is completed, the customer is able to see and query their output table and results.
A challenge faced in implementing this application was enabling multiple calls to the shared procedure from blocking/queuing other jobs running in LiveRamp’s BigQuery instance. To resolve the concurrency issue, we have better utilized BigQuery’s slot compute and expanded the number of slots available for our GCP project. Using slots has allowed us to split complex queries into upwards of 4000 smaller queries that can run in parallel.
Conclusion
The world’s most innovative companies are using LiveRamp’s embedded products. Indeed released a case study about how they leveraged LiveRamp’s AWS embedded offering to re-target their audience and how it helped them increase their response rate.Thinking through the solutions we have discussed in this post, we recommend a three-phased approach:
- Crawl to call the LiveRamp systems from the cloud of their choice (through a Rest API)
- Walk provides resolution and translation services to the customer in the cloud of choice. Your data stays in the same cloud and region but can pass to LiveRamp systems.
- Run provides resolution and translation services within your cloud account, ensuring that the data does not leave your account. This means that translation and resolution occur within the client's account, making this phase our ideal solution.
LiveRamp continues to innovate, and the future of embedded identity solutions includes the ability to run all resolution and translation services in the client's own cloud account through an easy-to-deploy mechanism. In the latest version of our offerings, we released immense performance gains. For now, our team is focused on advancing a new feature around precision versus reach configurability and customer experience enhancements.We are committed to improving our existing products and services by enabling more identity use cases for our customers. Check out our demo hub to learn more.