
LiveRamp engineering has a world-class infrastructure organization that supports the company’s developers who deal with big data on a daily basis. The Site Reliability Engineering (SRE) team helps bring best practices to new teams and focuses on infrastructure-as-code, monitoring-as-code, pipeline-as-code, CI/CD upgrades, log collection, self-service tooling, etc. We strive to help developers be more efficient and positively influence our customers’ experiences.
The challenge
At LiveRamp, many Windows clusters are running the services required to provide a secure experience for our flagship product, LiveRamp Safe Haven. As a platform that analyzes customer data, safety and security are always the first priority, and regular system patching is an important part of SRE’s charter.
Previously, we relied upon WSUS driven by Windows GPOs to patch our systems. However, as we have numerous systems with different security policies and firewall rules, creating a single, cohesive patching strategy with those tools was challenging. At times, preventing efficient patching. This resulted in a situation where we could not fully automate infrastructure patching the way that we wanted to, requiring manual intervention. Thus, we needed a tool that would allow us to patch easily, despite the complexity of our environments.
The solution: VM Manager
VM Manager is a suite of tools that helps manage the patching and maintenance of virtual machine estates, covering both Windows and Linux operating systems. It also helps drive efficiency through automation and reduces the operational burden of maintaining these VM fleets.
In total, it covers three distinct services:
- Operating system (OS) patch management
- OS inventory management
- OS configuration management
OS inventory management can collect and review operating system information, which helps the other two services interact with Google’s API.
Capabilities of VM Manager OS patch management
VM Manager’s OS patch management functionality has helped us resolve these issues. It is a built-in tool provided by Google, which integrates well with our GCP resources. It even supports patching machines without direct internet access or connectivity to a WSUS server. It allows us to define a schedule of the patch jobs, including which servers we want to patch, how many at a time, and which patch updates we want to apply. Additionally, we can apply pre- and post-patch scripts to these patching schedules to support whatever custom operations each system or environment needs.
Integrate Terraform with OS patch management
As with VM Manager’s config management, we can leverage Terraform to ensure that our patching configuration is source-controlled and in a known state. Additionally, reusable modules can make it even more convenient for us to quickly and easily transplant our OS patching configs to any new environments we may need to support or create.
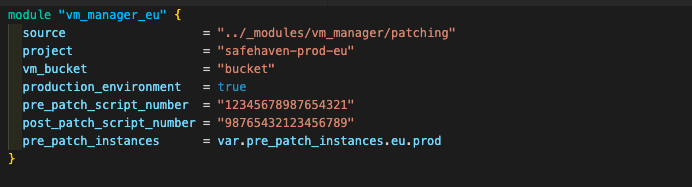
Hypothetical example
As our infrastructure requirements are constantly growing and evolving, we have to be able to react accordingly. Whether adding more servers or consolidating resources, we should not spend excess time on manual executions. By taking advantage of Terraform combined with OS patch management, all the environments with patching policy applied will quickly adapt to any changes we introduce in the future.
Furthermore, as we don’t want to patch the entire estate simultaneously, we’ve broken them into different patching groups. These patching groups are scheduled sporadically throughout the day, during our lowest point of activity. In the course of ordinary operations, we would schedule the workflow to trigger once a month. Based on our execution schedule, our pre-patch configurations would run first. For example, the pre-patch script nested in this job could trigger notifications to a Slack channel or to pause PagerDuty alerts etc.
After these steps are complete, we would then initiate patch-job1. Our server platforms are highly available, so we’ve split the VMs performing the same roles between the different patch jobs. As such, until this job completes, patch-job2 is unable to execute, decreasing the risk of platform downtime due to patching. Of course, if everything goes smoothly in patch-job1, patch-job2 will patch the rest of the servers in the environment.
Finally, after all of our infrastructure patching jobs are complete, our post-patch job reenables PagerDuty alerts and notifies the Slack channel that patching was successful.
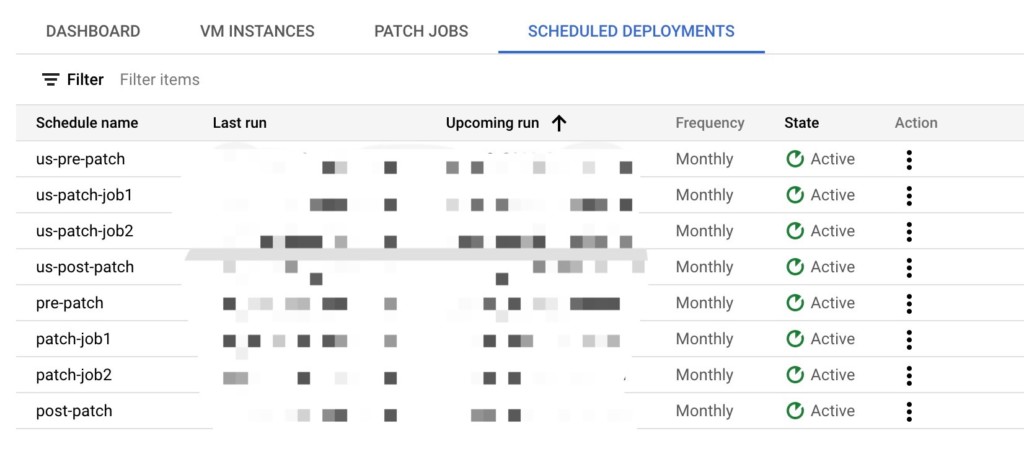
Drilling down into these patch jobs from the dashboard, we can quickly review any servers included in each patch job and understand the patch status of the entire group at a glance.
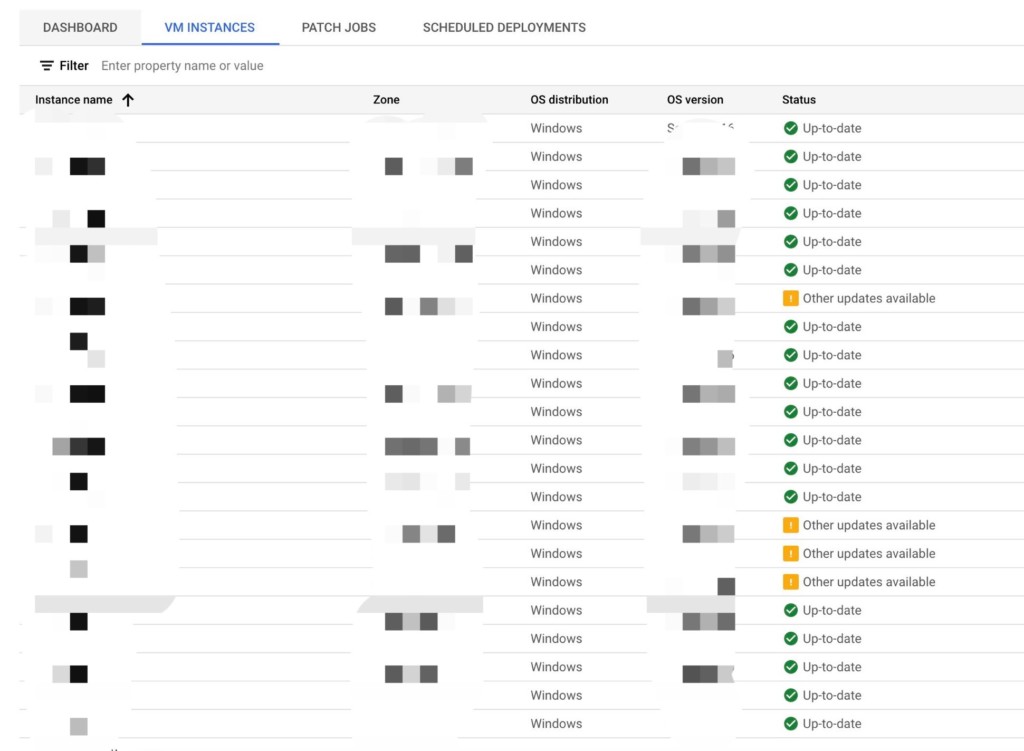
Google’s VM Manager’s OS patch management is exactly what we need and allows us to serve our customers’ needs efficiently and effectively.
LiveRamp is a data enablement platform designed by engineers, powered by big data, centered on privacy innovation, and integrated everywhere.
We enable an open web for everyone.
LiveRamp is hiring! Technical Careers@LiveRamp. Subscribe to our blog to stay up-to-date!